Machine Learning for Football Player Market Value Prediction

This article is more about sharing insights and key takeaways from my journey of 10 days with the project rather than explaining code implementation. if you’re here for the code - check out github !! and for model details - It’s actually live!! Okay, Let’s begin !!
Day 01: The big idea & The not so serious plan
Every ambitious project starts with a deep question, a bold vision, or a strong sense of purpose. this one? nah, it started with me liking football and thinking, hey, predicting player market values sounds kinda fun. no groundbreaking mission - just vibes, curiosity, and a questionable amount of free time (guess?? its 60+ hours).
The plan?
Sure, this is a for fun project, but that doesn’t mean i can’t throw in some serious objectives (objectives just to tell how brialliant i am, not going to complete all ,yes it’s a spoooiler):
- accurate player valuation - so clubs don’t burn millions on overhyped players (looking at you, chelsea) .
- transfer market efficiency - helping clubs make better financial decisions (not that they’ll listen).
- talent scouting & risk assessment - maybe i’ll identify the next big star before real madrid does.
- data-driven insights - because gut feeling is cool, but numbers don’t lie (unless they do).
PS: All my codes/resources during the project are publicly available on my github
How i’m tackling this??
- scrape data from sofifa (because why download when you can make life difficult?) shoutout to yula sozen for saving my time thinking where to scrape.
- clean the messy data (because as we know real world data is never as neat as kaggle ).
- exploratory data analysis (aka playing with graphs and pretending i found deep insights 😅 for me).
- feature engineering (essentially making up new data out of old data, but in a smart way- This is gonna be costing my valuable time soon).
- train some models (starting with linear regression bc tradition - they say).
- experiment with other models (probably overcomplicating things here- this is fun by the way).
- deploy the best one (deployment really sucks, i hate this part but i fun hating haha).
Sounds simple, right? yeah, spoiler: it won’t be with features !!!
so that’s day 1 - planning, overestimating my skills, and mentally preparing for future debugging sessions that will make me question all my life choices.
Day 02: Web Scraping
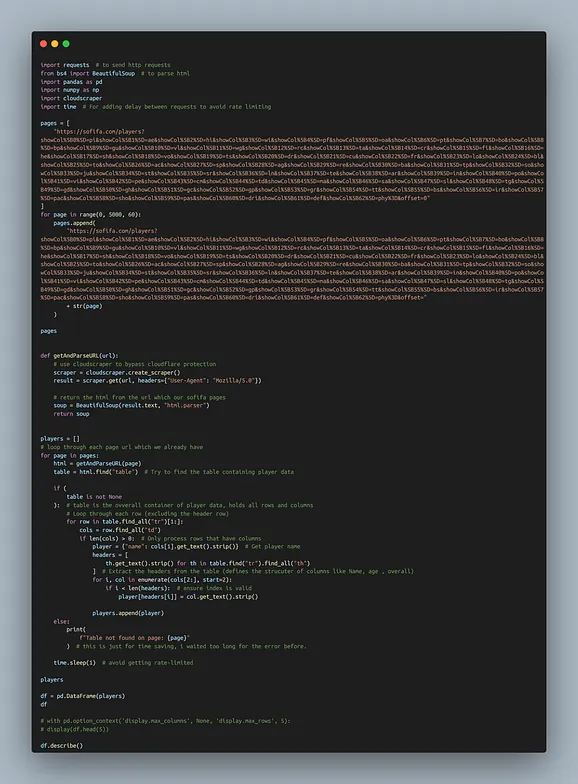
if you’ve ever tried web scraping, it’s easy part, i am not going to say it’s hard. but but the plan with no twist and turns, i’m not considering it plan/
since sofifa doesn’t offer a clean dataset for download, i had to scrape it myself. simple plan, yes it’s simple so i don’t have to say it.
- send a request
- use beautifulsoup
- store it in a dataframe
PS: all the players data i scraped was updated on February 2025
sounds easy, right? wrong.
- cloudflare protection. sofifa wasn’t having it, hitting my requests with 403 forbidden. tried tweaking headers, adding delays, and pretending to be human no dice. solution? cloudscraper ez. it bypassed cloudflare, letting me scrape the data without triggering alarms. data scraped: success!
[other]data after scraping[/other]
All the codes/notebooks are available on github !!!
Day 03: Cleaning the messy data
after scraping, my dataset looked terrible. missing values, inconsistent formats, and some players with market values so high they might own the clubs instead. so it was time to clean up this mess with a plan.

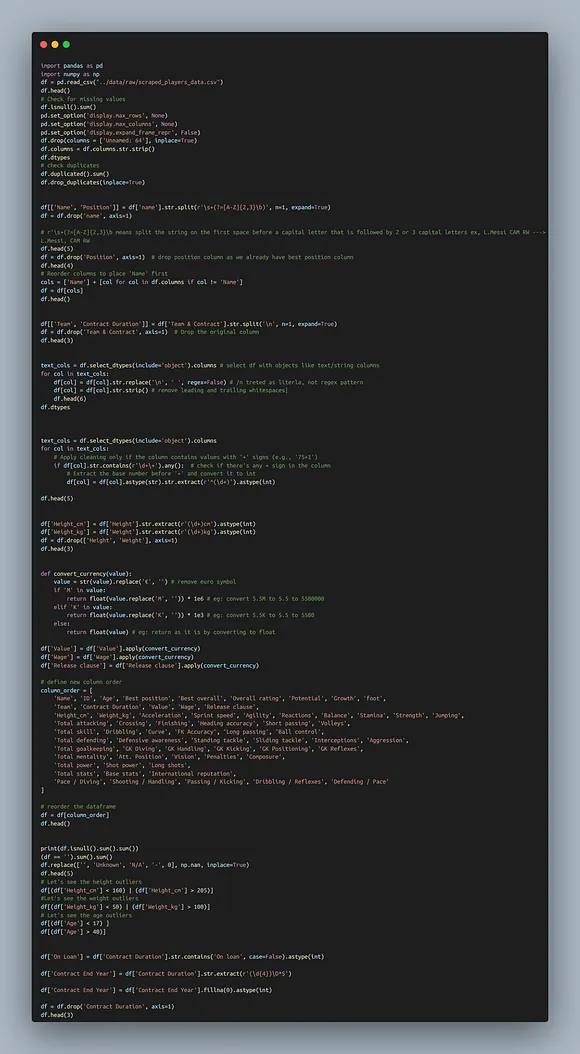
And this is what my data is looking after performing cleaning !!
[other]data cleaining process[/other]
All the codes/notebooks are available on github !!!
Day 04: Performing EDA
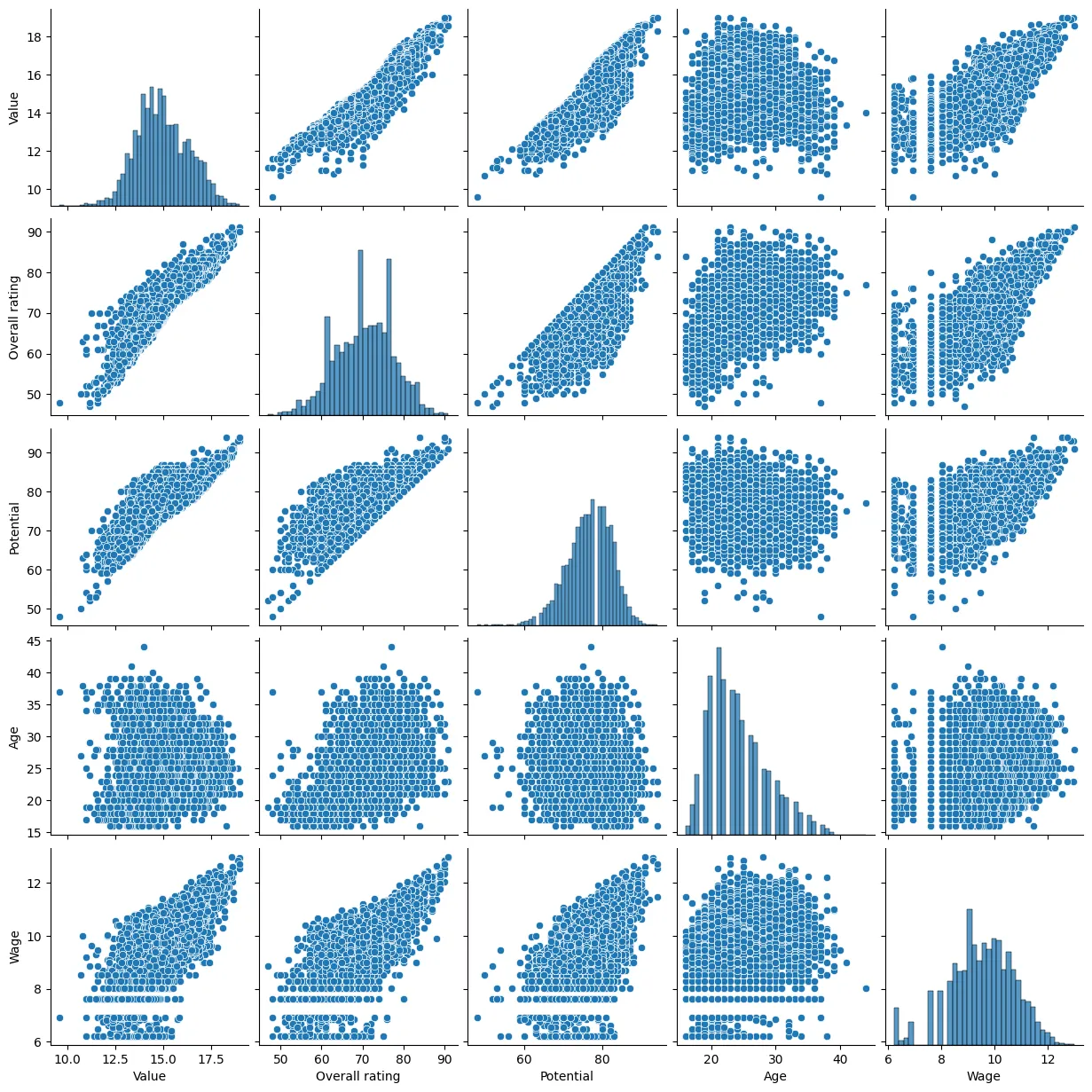
this day was all about visualizing, because let’s be real, it’s way easier to connect with numbers when they actually look good. so, i turned to plotly, because it’s interactive, and i’m a beginner who loves shiny visuals with minimal coding effort.
Overall dataset insights
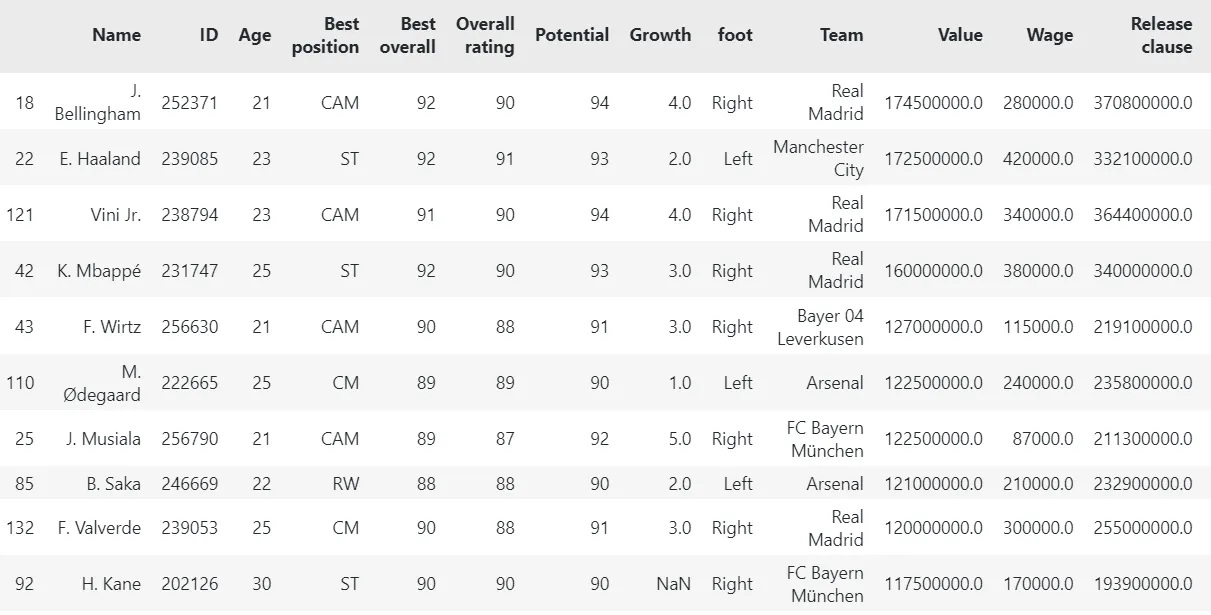
- what are the top 10 most valuable players?
- how does market value vary by position (e.g., are strikers more expensive than defenders)? (spoiler: strikers usually win the ‘expensive’ game, but it’s always nice to check).
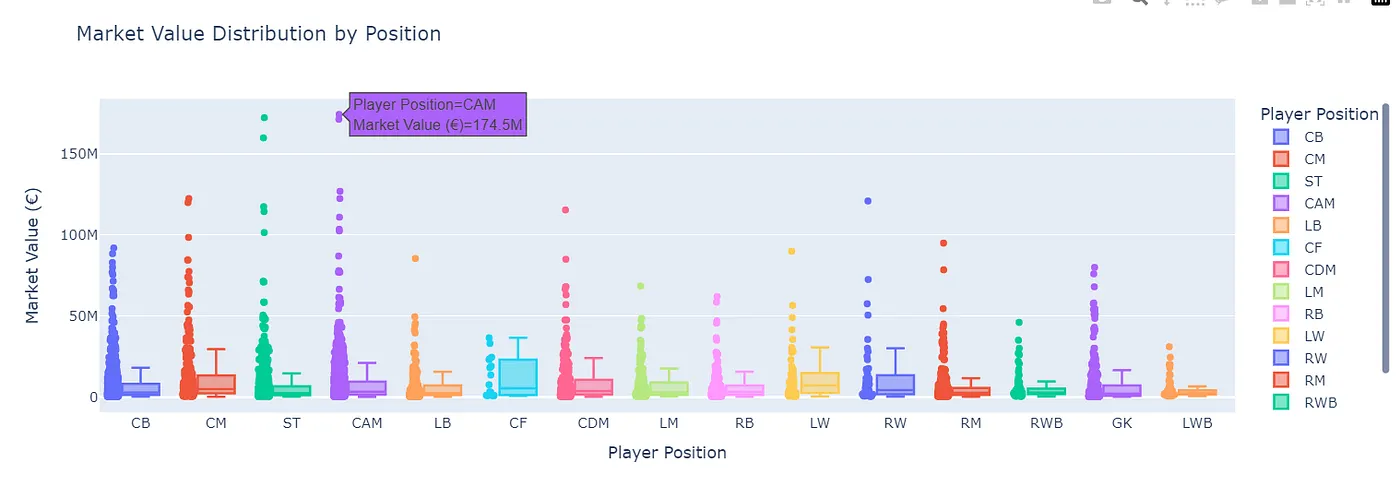
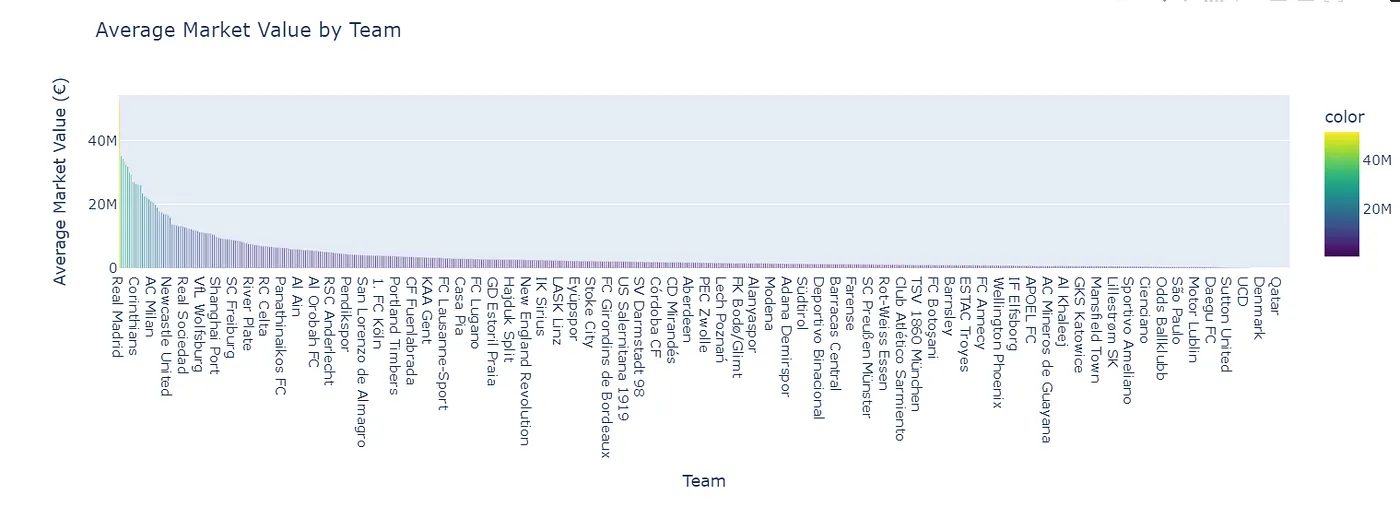
- which teams have the highest average market value? (i wonder if the rich clubs are richer than others - answer: yes)
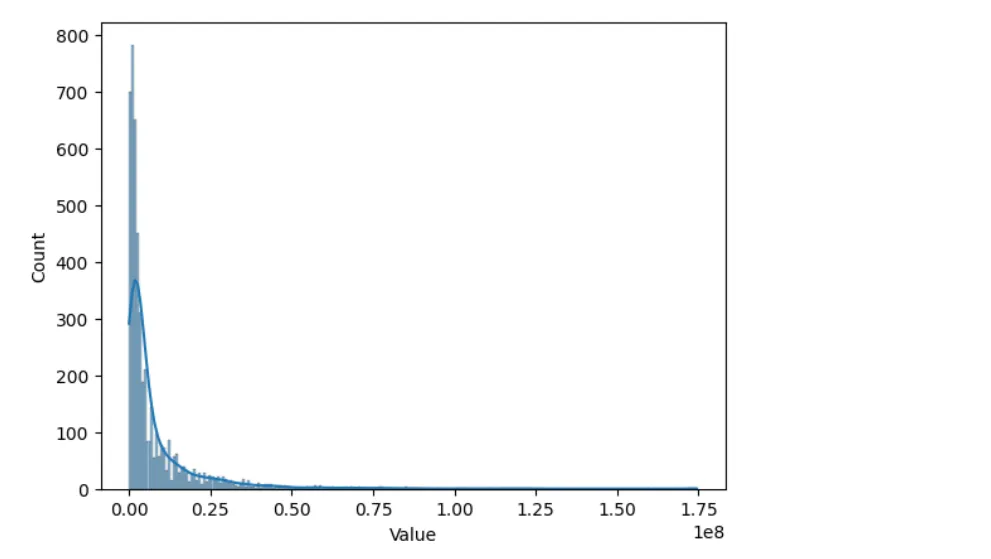
- what’s the distribution of market values (is it skewed towards a few expensive players)? ( extremely skewed, it’s like most of the market is monopolized, but we are going to fix it with log transform)
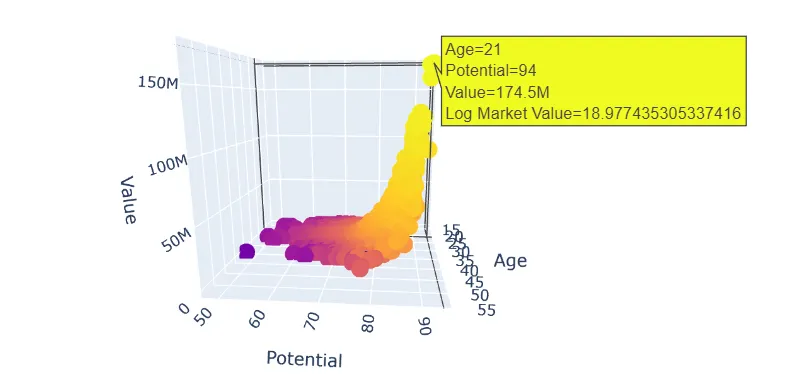
- how does age correlate with market value (are younger players generally worth more)? (turns out youth is not always a guarantee of a high price).
Player attributes vs. Market value
- how does a player’s overall rating affect their market value? (of course, higher ratings mean higher prices).
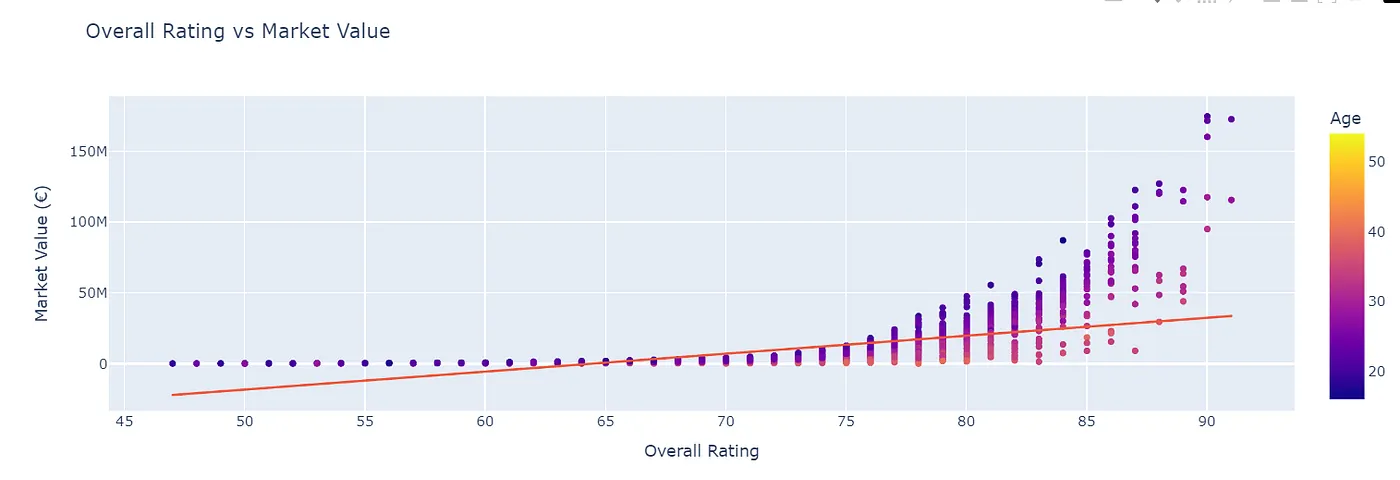
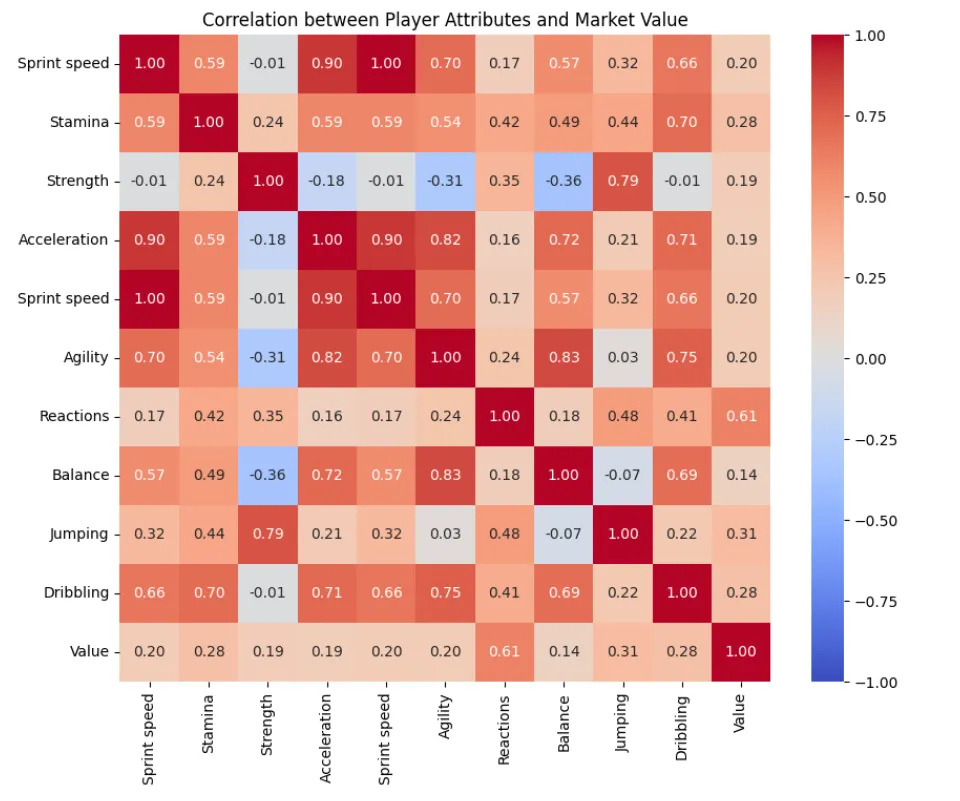
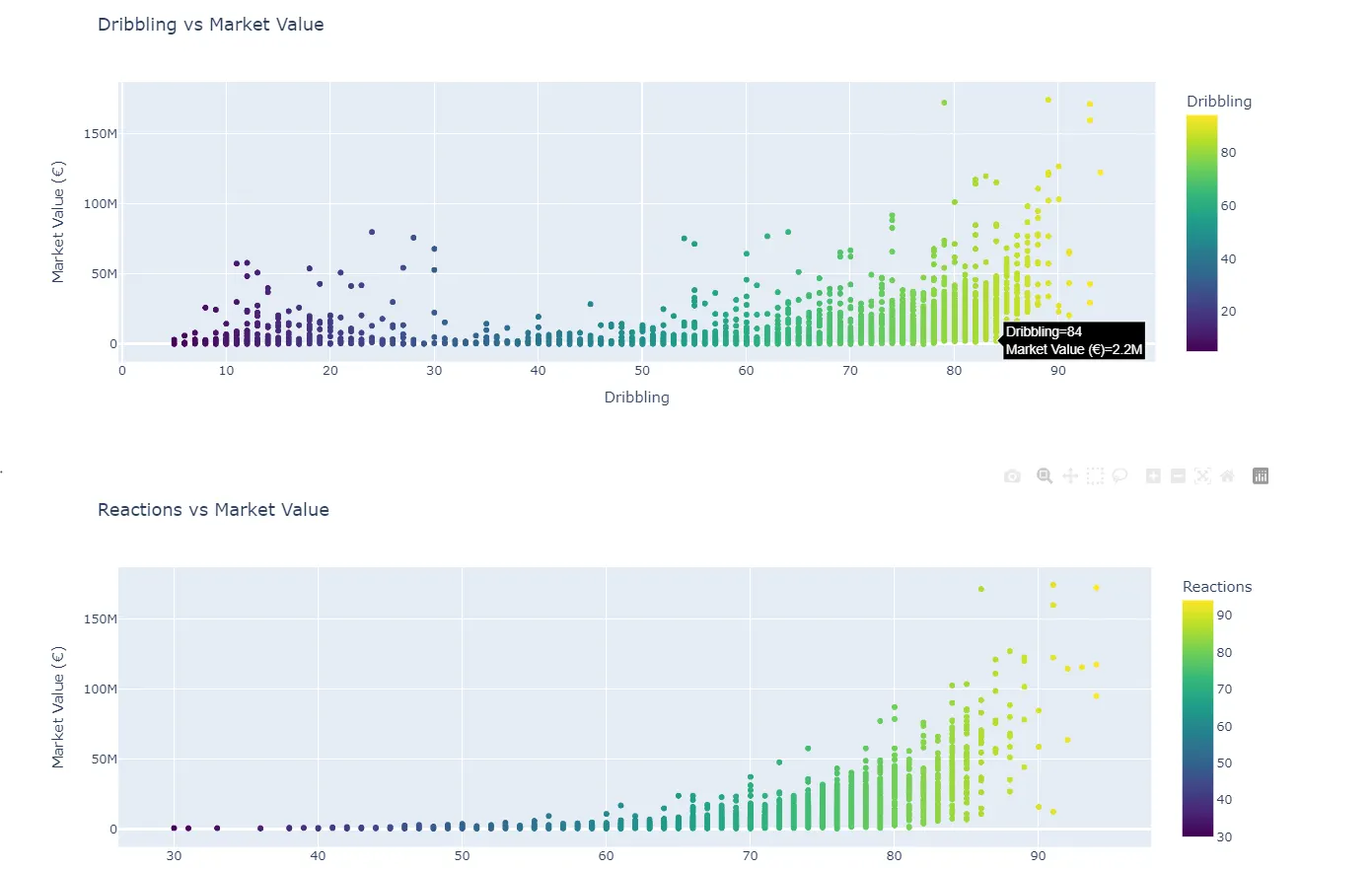
- which individual attributes (e.g., pace, stamina, strength) correlate the most with market value? it’s all about that reactions, stamina most.
- does international reputation (1–5 stars) impact market value? (it does a little bit, so we will consider it as input too)
- how do potential ratings compare to market value (are high-potential players priced higher)? (Obviously, high potential players have high market value, but it is too correlated with our data, so we have to remove it from features).
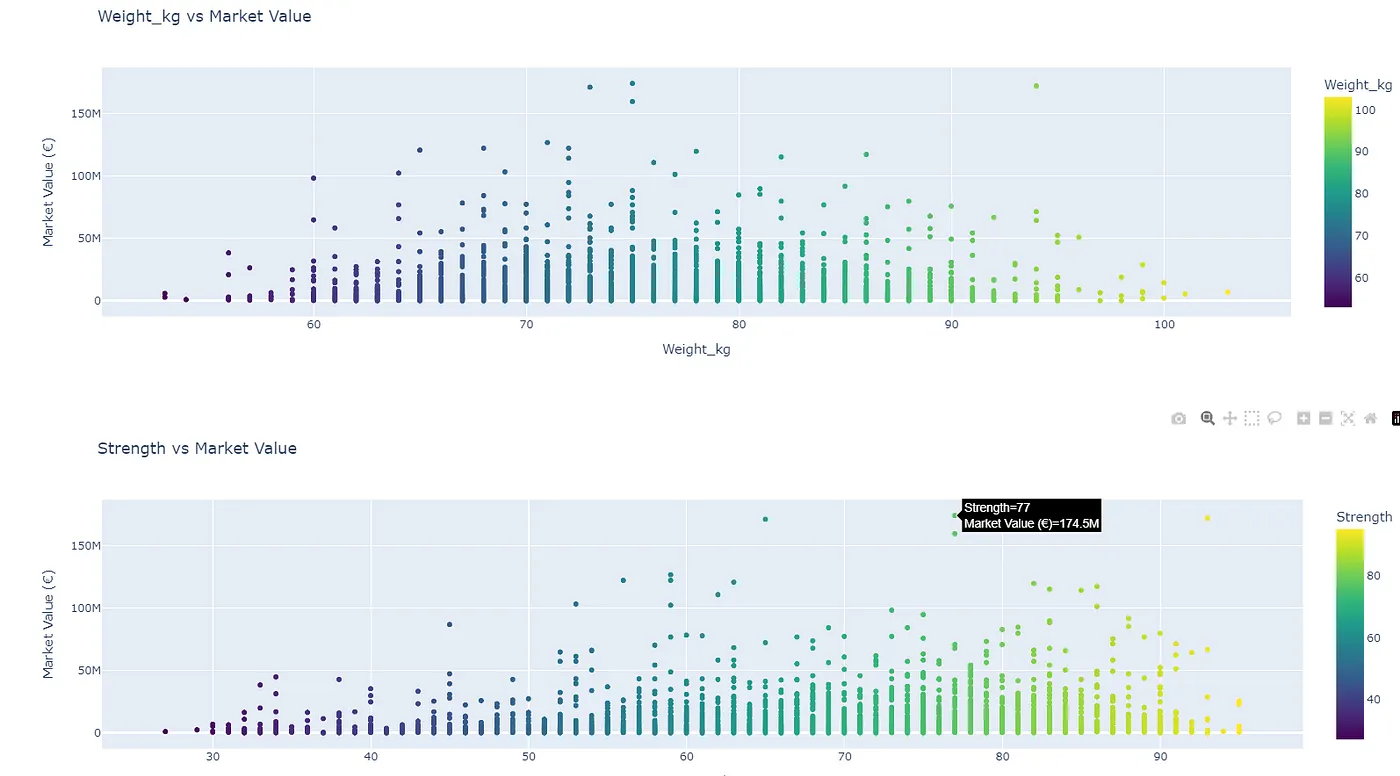
- do physical attributes (height, weight, strength) play a role in market value? (height does not always mean higher value similar for strength and wieght too).
Position-specific insights
- are attacking midfielders (CAM/CM) more valuable than defensive midfielders (CDM/CM)? (surprise, attackers have the edge).
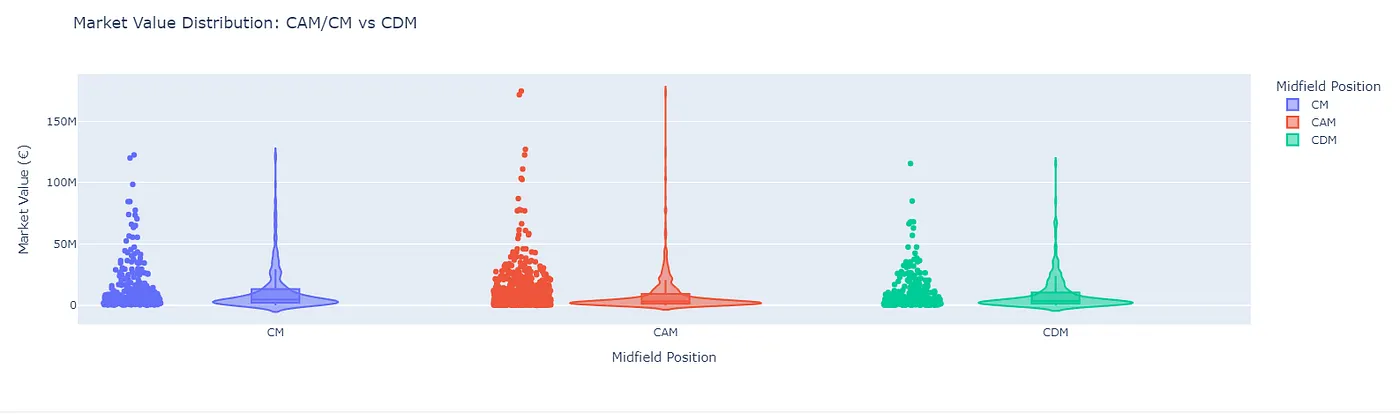
- how does pace affect wingers’ (LW/RW) market value? ( fast wingers make a lot of money for sure)
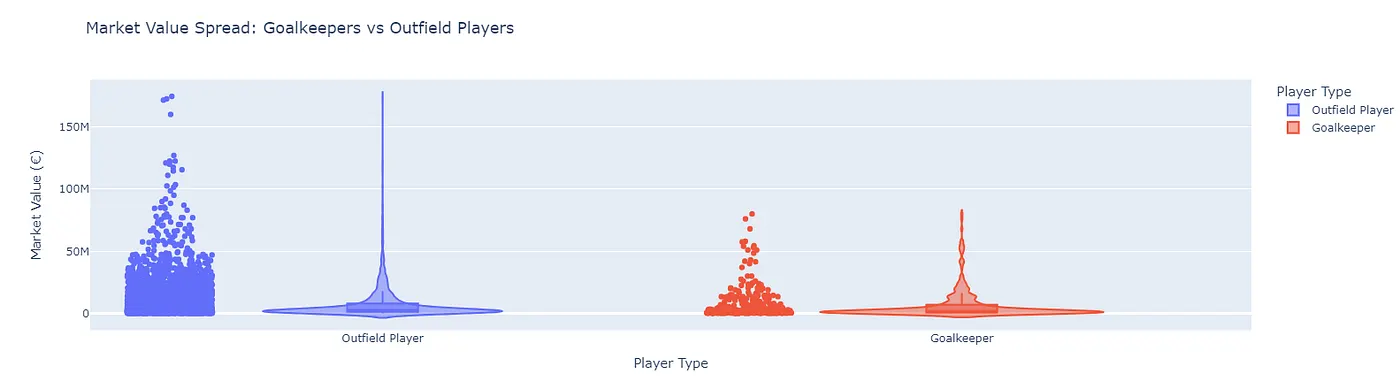
- do goalkeepers follow the same market trends as outfield players? (nope, they have their own unique market dynamic, so we have to define our category for prediction later)
Contract & Transfer market impact
- does a player’s contract end year affect their market value (e.g., do players with 1 year left have lower values)? (hint: yes - players nearing contract expiration tend to lose value).
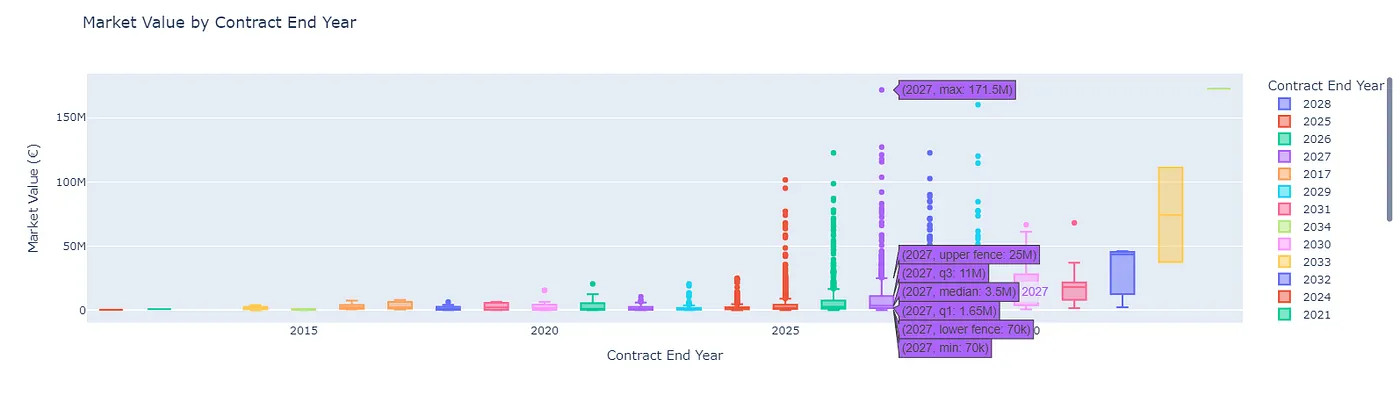
- are players on loan priced differently compared to permanent squad members? (yes, loan players tend to be valued less).
and with that, it was time to take a deeper dive into how all these factors might shape the models down the road. but visualizing was just the beginning… i am about to do the biggest mistake for upcoming days with my project.
All the codes/notebooks are available on github !!!
Day 05: Feature engineering I : (creating features, transforming features)
This is where i am going to make mistakes and mistakes, but , no worries, i’ll fix them later. just gotta embrace the chaos for the next 3 or 4 days and learn from it! I have make some plan with the help of ai tools, and just followed them for my feature engineering
1. position-based features:
i grouped players into categories like attackers, midfielders, defenders, and goalkeepers, assigning scores based on those. still a work in progress, gonna refine this tomorrow .
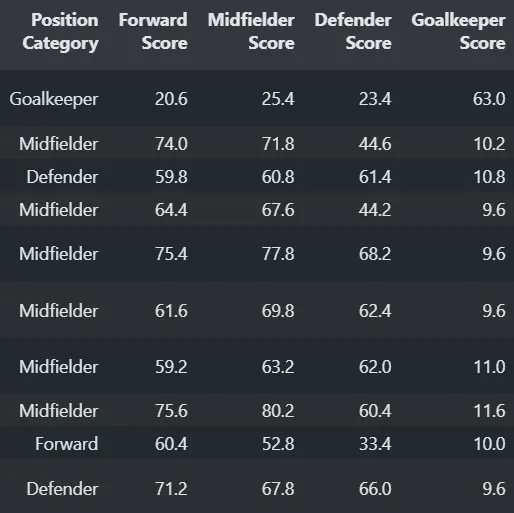
2. club-based features:
switched from one-hot encoding (bc let’s face it, the curse of dimensionality was ruining my life) to target encoding. now using the mean market value for each club to represent the club. much cleaner and should work better.
3. contract-based features:
so, correlation with market value was basically neutral. players’ contract features, aside from age, overall rating, and potential, didn’t seem to hold much significance. well, that’s a bit of a letdown, but at least we know.
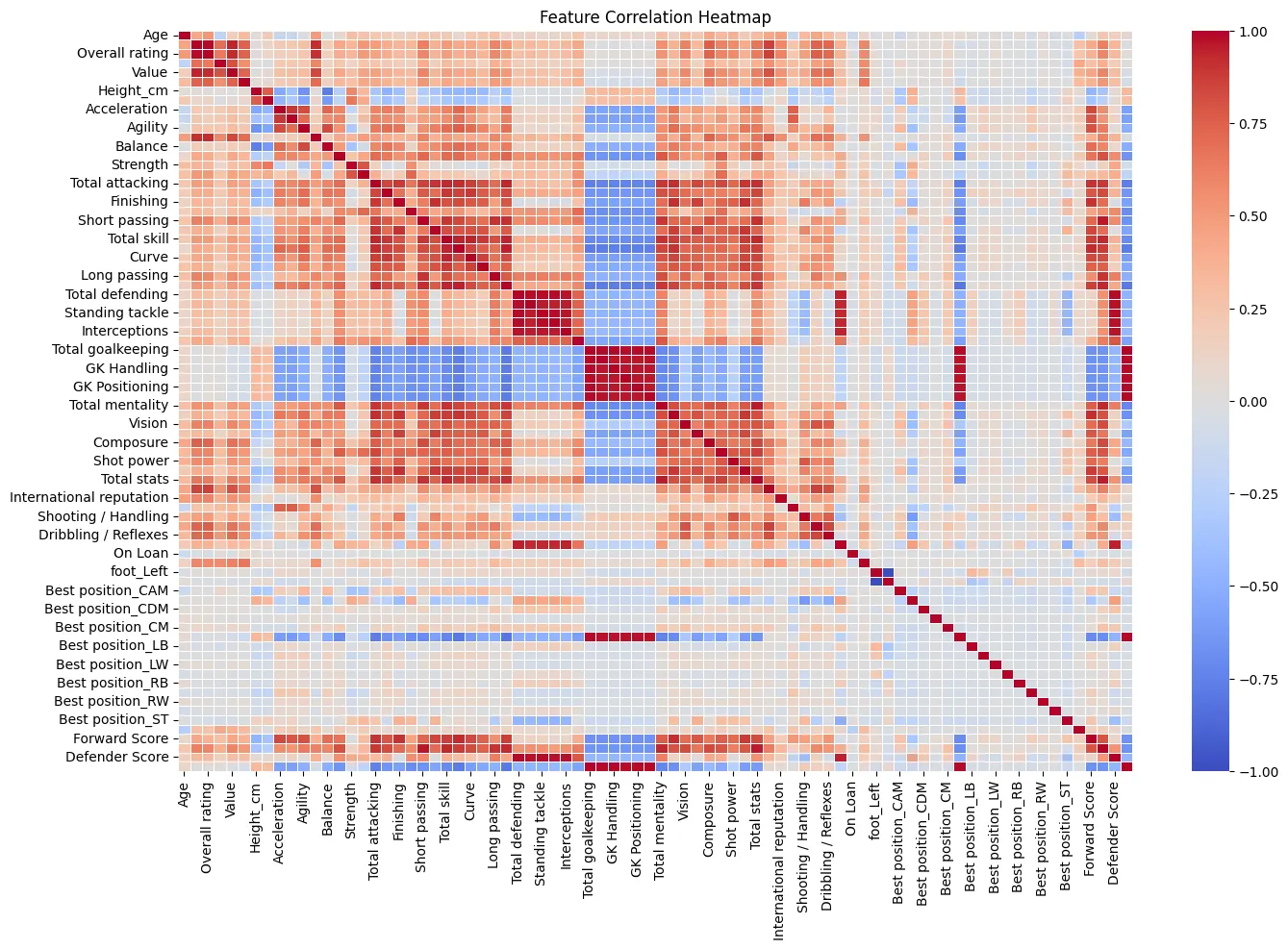
Day 06: Feature engineering II , Diving into Linear Regression and a short streamlit setup for deployment.
Yo, so here’s where things got real interesting. after all the data cleaning and stuff with features again,
Ifigured i’d start with linear regression just to get a feel for the data. ran it and… a solid r² score of 0.52? yeah, not bad, but not where i wanted to be. it was clear the features needed some work.
After some feature engineering - tweaking features, adding new ones, and generally just messing around with things - the model’s r² score shot up to a pretty solid 0.96. and this was with just the numerical features. i was feeling pretty good, but i knew i could push it further.

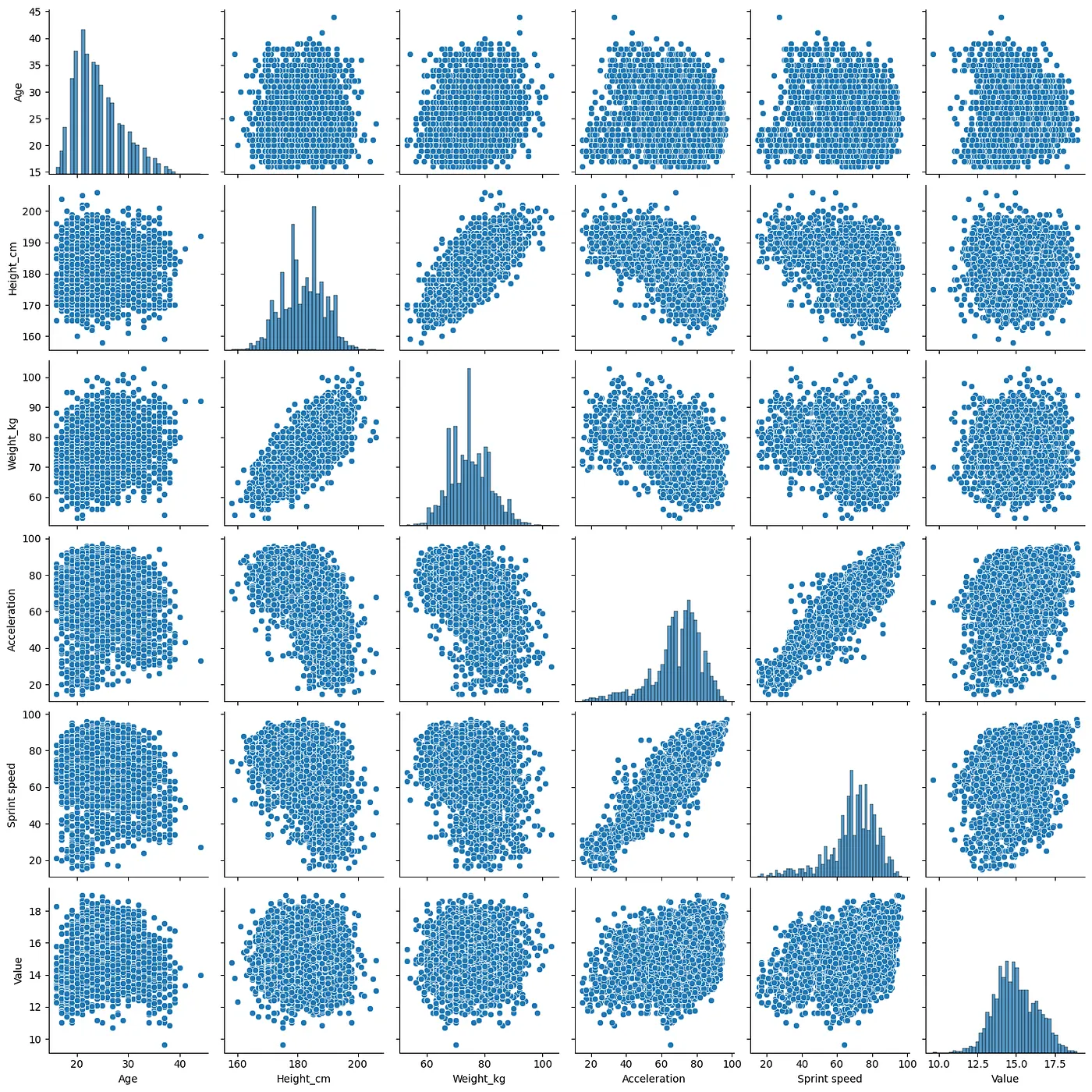
here’s the kicker: i still wasn’t fully happy with the result. i had to rethink feature selection and engineering, so i decided to convert every single feature into numerical values. i applied scaling, some transformations, and ran the model again. bam! r² score shot up to 0.97. that’s when i knew it was time to save the model.
next, i figured i’d try deploying it locally with streamlit - easy right? well, no. adding a user input form and dealing with inverse transformations was hands down the worst part of today (not gonna lie, i almost lost my mind there). but hey, managed to get it working, so at least i could throw predictions around in the app, even though it’s not perfect yet.
All the codes/notebooks are available on github !!!
everything seemed to be going really well at first, and i was feeling good about my progress, but soon enough, things started to take a turn. i hadn’t realized that my focus on feature engineering and my greed for deploying - especially trying to take user inputs and transform them - was making things way more hectic than necessary. mistakes i made included not properly reducing features when needed and not paying enough attention to the importance of each feature. at the time, i was so caught up in pushing for deployment that i didn’t fully understand the impact of these steps, and instead of improving, things started worsening. it was a much-needed wake-up call to refocus and adjust my approach.
Day 7: Streamlit setup - making it work (somehow)
alright, so yesterday was… chaotic. let’s just say deployment isn’t exactly my comfort zone. when i started setting up streamlit, i thought, how hard can it be? turns out, the answer is very.
between formatting inputs, making sure they match the model’s expectations, and ensuring everything flows smoothly, i found myself in a weird debugging loop. sometimes the model expected numbers, sometimes strings, sometimes sacrifices to the coding gods. by the end of the day, things were kinda working, but i wasn’t happy with it.
- today’s mission: just make it work -
i wasn’t going for perfection. i just wanted a functional ui where: ✅ users could input player attributes ✅ those inputs would get transformed into model-friendly values inside streamlit ✅ predictions would actually make sense
so, after a lot of trial and error (and a bit of questioning the choices /inputs), i finally got it running.
but what about model tuning?
yeah, yeah, i could’ve spent today testing better models or tweaking hyperparameters. but honestly? finishing what i started felt more important. there’s something oddly satisfying about getting one thing fully functional before moving on to the next shiny idea.
- demo time -
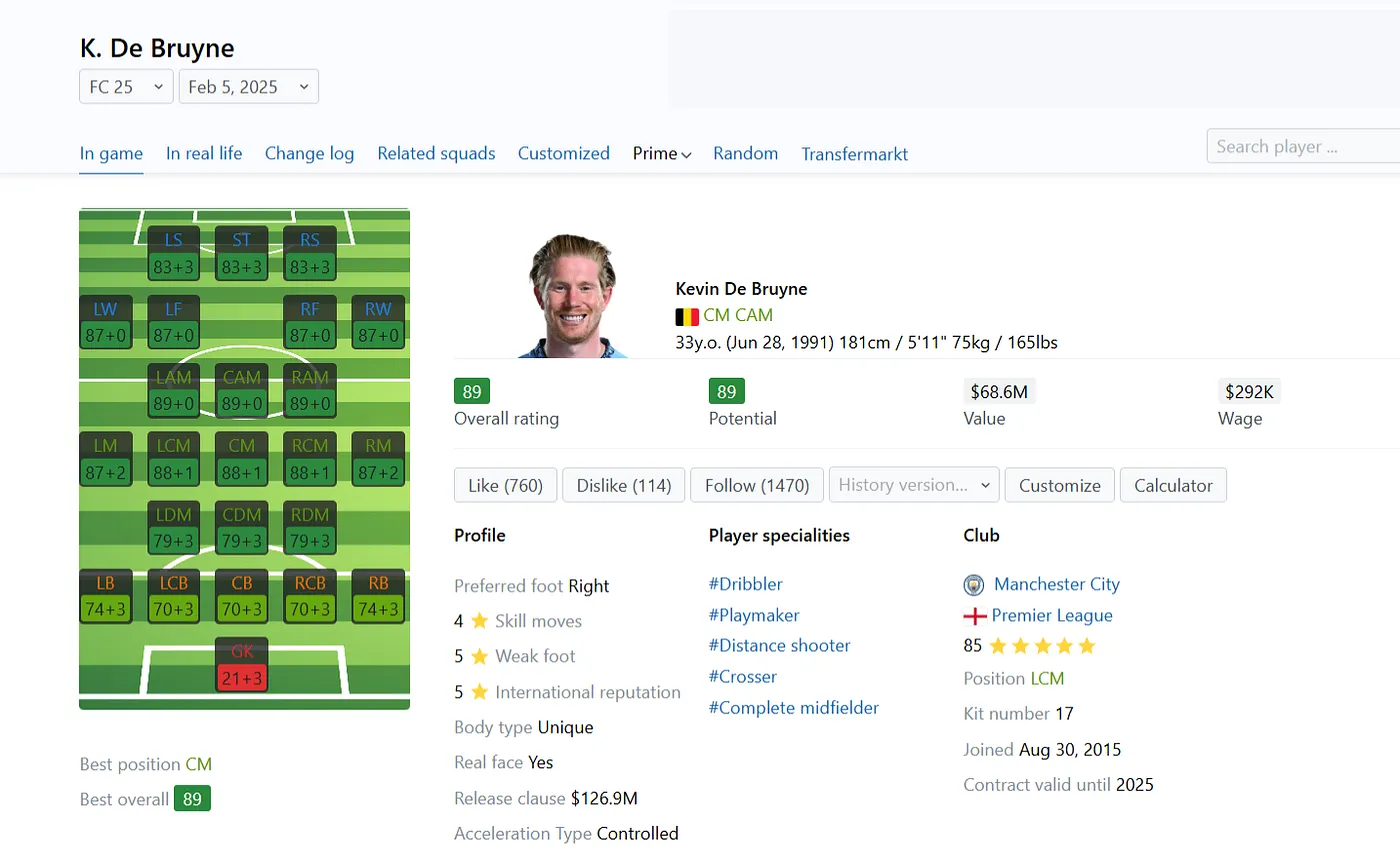
this was hands down the best part of the day when i was doing that. i pulled real data from sofifa, ran it through the model, and , surprisingly - the predictions made sense.
the accuracy? hovering around 90% across all positions, which is way better than i expected for a first attempt. i mean, this is just linear regression - basically the “starter pokemon” of ml models. if it’s already performing this well, imagine what ensemble methods or neural networks could do.
but that’s a problem for future me, and i wasnot still aware what am i going to face in future with my features selection !! for now, i’m just vibing with my first deployed model.
kevin de bruyne (kdb): actual vs predicted
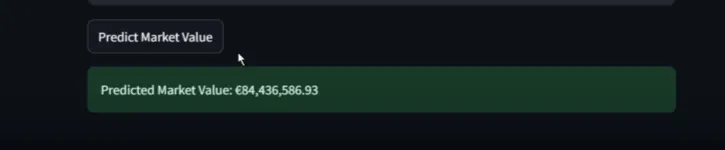
lamine yamal : actual vs predicted
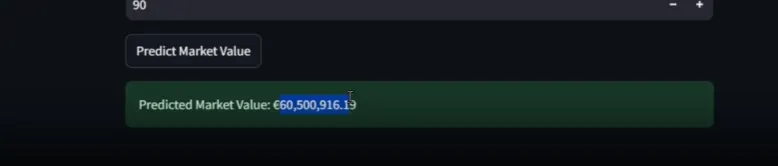
jan oblak : actual vs predicted
All the codes/notebooks are available on github !!!
Day 08: Testing Ridge, Lasso, and Decision Trees
This day again, i have no idea about the mistakes, and again vibing with my accuracy. haha
Insights from that day:
This day was wild. started off like a responsible data scientist - handling outliers in my linear regression model. expected some magic, but guess what? zero improvement. yep, all that effort for nothing. welcome to machine learning, where sometimes, you just waste time elegantly.
- The great pca experiment -
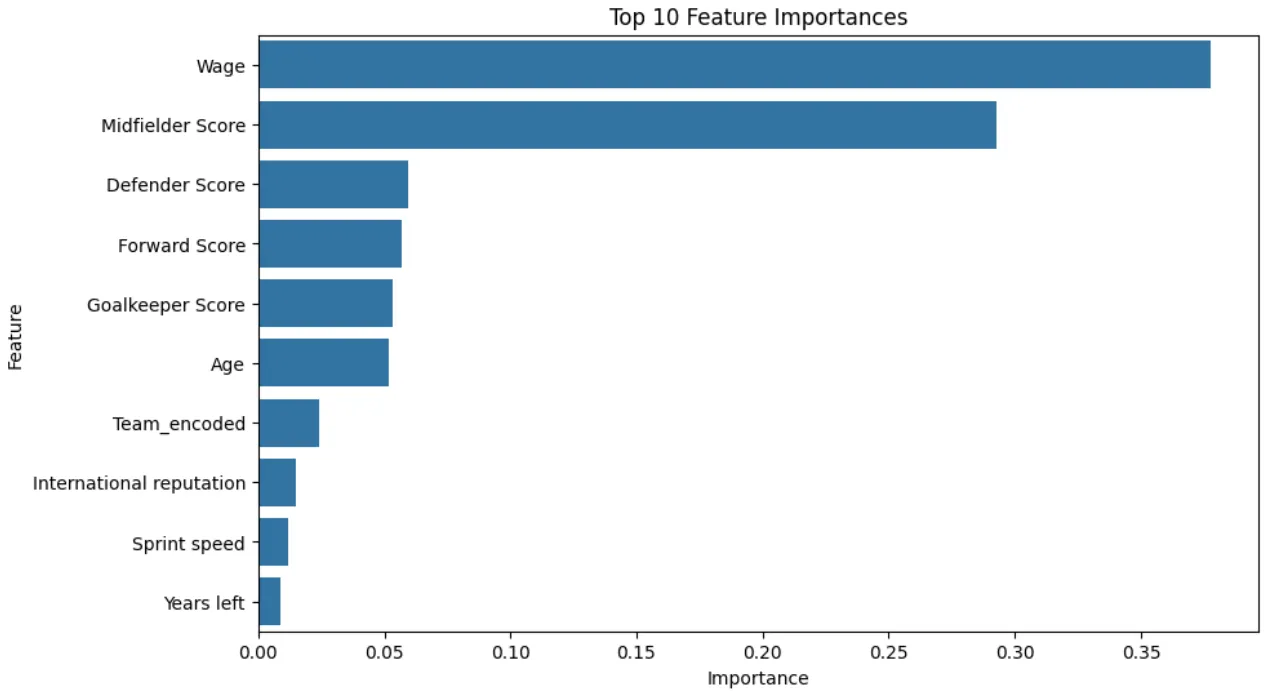
since the outlier drama was a flop, i decided to unleash pca on my dataset. after converting everything into numerical features (because models don’t speak football, only numbers), i reduced my features from 50 to 40. and boom! the model accuracy jumped to 99%!
but wait, before i start celebrating… i know deploying a pca-transformed model is like solving a rubik’s cube while blindfolded. the reverse transformation during predictions is a nightmare i wasn’t ready to deal with. so yeah, my 99% accuracy? completely useless for now. 😭
- ridge vs. lasso: the regression deathmatch -
next, i dived into ridge and lasso regression like a football coach picking his best midfielders.
- ridge regression: performed like a champ, outclassing linear and lasso models.
- lasso regression: tried its best, but meh… ridge had the better game.
so, for now, ridge is my starter unless some other model comes in with a better offer.
- Decision tree: overfitting? let’s find out -
finally, i ran a decision tree regressor. without any tuning, it gave me a 0.98 R² score, which was kinda crazy. but i wasn’t fooled - decision trees love overfitting more than chelsea loves spending money on midfielders.
so, i visualized it… couldn’t make much sense of it (yet), but i knew one thing - this tree was too deep (pun intended).
then i tried hyperparameter tuning to keep it in check. result? not much of a difference. so basically, i spent two hours tweaking knobs just to get the same performance. classic ml struggle . 😅
[other]ridge lasso decisiontree[/other]
All the codes/notebooks are available on github !!!
Day 09: Had to hit reset from Feature Engineering 😫
today was one of those days - the kind where you realize you’ve been making a massive mistake for days, and it hits you like a red card in the first five minutes.
Insights from that day:
When exploring and finding why is i am getting soo much accurate model?? i had my “oh no, i’ve been an idiot” moment. since day 4, first feature engineering, i was obsessing over how to reverse transform features for deployment. but guess what i completely ignored?
the features i was using were way too correlated with market value. turns out, best overall, overall rating, and potential were doing all the heavy lifting in my model. the 99% accuracy? fake. it wasn’t actually learning anything useful - it was just memorizing the most obvious stats.
so how bad was it?
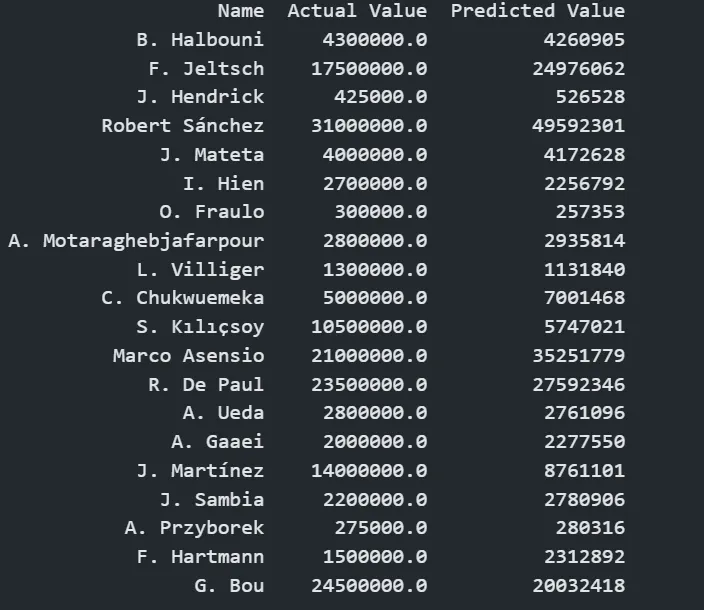
I had already deployed the model locally with streamlit. i even tested it with real players like: kevin de bruyne (KDB), lamine yamal and jan oblak
and you know what? the predictions looked great. why? because my model was basically just looking at those three inputs and calling it a day. it was like a student who only studies from leaked exam papers - of course, they score high, but do they actually know anything? nope || Wow the example is greate nah 😅
so yeah, my entire feature engineering approach? trash. i need to rebuild everything from scratch. again.
but here’s the weird thing - for the first time in my journey, i actually feel like i’m learning. like, this isn’t just about tweaking hyperparameters or optimizing a few numbers. this is real problem-solving. it sucks, it’s frustrating, but at the same time… this is what real machine learning is.
Day 10: The Finish line: deploying my first project
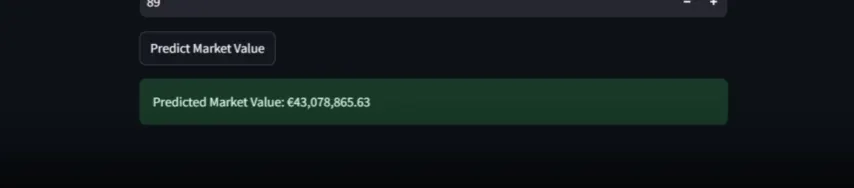
it’s live! after 10 days of non-stop grinding, debugging, and occasional existential crises, my first end-to-end ml project is finally out in the wild! 🎉
Wanna check it out? here you go: football market value predictor
- polishing the rough edges -
today was all about cleaning up my mess. after some final feature engineering tweaks, i managed to get the model accuracy up to 85% - a pretty solid baseline. but you know me, i wasn’t gonna stop there.
so i spent about an hour fine-tuning hyperparameters, and boom! accuracy climbed up to 89%. not bad, right?
- the real game-changer: ensemble learning -
this is where things got exciting. i threw a few ensemble methods into the mix, and after testing a bunch of them, gradient boosting absolutely crushed it. accuracy jumped all the way to 94%, making it the clear winner for deployment.
and just like that, after 10 days of non-stop learning, experimenting, and sometimes just hoping for the best, i’m officially closing this project.
it’s been a wild ride - full of surprises, some unexpected bugs, and a whole lot of fun. but most importantly, i learned a ton, and this is just the beginning.
if you wanna check out the code and maybe even build on it yourself, here’s the repo: 👉 GitHub Repo
what’s next? well, i’ve got a ton of ideas brewing, but for now… i’m gonna enjoy this win.
Enjoyed the read? give it a 👏for the motivation!